Overview
什麼是Machine learning?
Machine -> Automatic
Learning -> Performance is better
任何裝置的行為會被過去的經驗影響。(Nilsson 1965)
系統重複執行相同類型的任務會越做越好。(Simon 1983)
從資訊處理的任務漸漸提升資訊處理的能力。(Tanimoto 1990)
Machine Learning為實現人工智慧(Artificial Intelligence)的一種方式,其涉及機率論、統計學、逼近論、凸分析、計算複雜性理論等多門學科。Machine Learning主要目的在於讓電腦能有「自主學習」的能力,以機器學習演算法實現之。機器學習演算法是從大量資料中自動分析其規律,並根據規律對未知資料進行預測的演算法。
Machine Learning的應用
- 語音辨識
- 交通工具
- 無人駕駛技術
- 判斷恐怖份子
- 分類星體
- 下棋
等等等...
機器學習分類
Supervised Learning:透過具有標籤的訓練資料,讓機器學習資料輸入與輸出之間的規則。classification, regression
Unsupervised Learning:尋找無標籤資料之間的群聚關係。clusering, density estimation
Semi-supervised Learning:僅有少許部分訓練資料具有標籤,藉由這些具有標籤的資料,預測其他無標籤的資料,再進行Supervised Learning。
Reinforcement Learning:機器在學習時對於每次出來的結果作評分,機器根據分數慢慢修正自己,以學會某項任務。
例子:
有很多車子,其上標籤出哪些是跑車、哪些不是跑車。
為車子的價格 為引擎的大小
每一台車可以表示成:
而表示是否為跑車 ->
每個訓練資料通常以一個pair表示之
如果有N筆資料,可用集合表示成:
假設訓練資料的分佈如下圖所示:
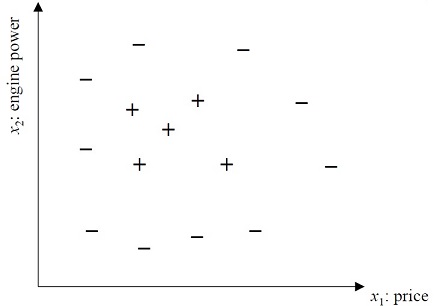
假設一個Hypothesis Class:
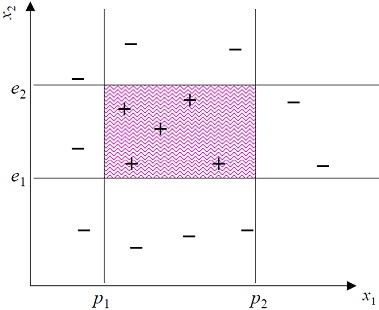
根據資料分佈,我們設定跑車須符合下列式子:
然而有一個標準答案,稱作Concept Class(Actual Class)如下:
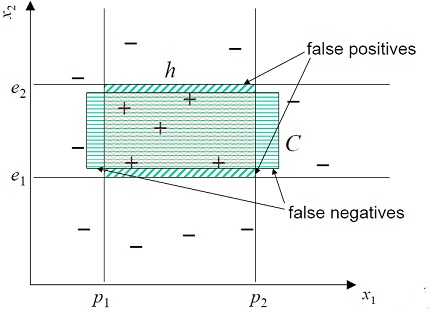
false positives:根據hypothesis class,我們預測為positive example,而正確答案為negative example。
false negetives:根據hypothesis class,我們預測為negative example,而正確答案為positive example。
如果hypothesis class h對於trainning datas X 完全正確,我們稱h is consistant with X。
Hypothesis Choice
根據上例的訓練資料,可以做出最保守的選擇S,與最寬鬆的選擇G:
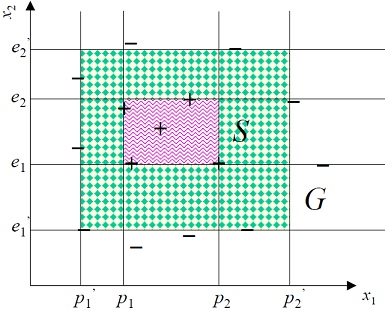
S:Most specific hypothesis choice
G:Most general hypothesis choice
我們能有許多hypothesis choice,如何選擇最好的hypothesis choice,是Machine Learning非常重要的議題。
What is Machine Learning
by Pedro Domingos A few useful things to know about machine learning Communications of the ACM, Vol. 55 Issue 10, 78-87, October 2012 .
Machine Learning = Representation + Evaluation + Optimization
Representation:選擇可學習之hypothesis space。
Evaluation:評估這個hypothesis space的好壞。
Optimization:從hypothesis space中找出最佳化模型的演算法。
The Basic Learning Concept
Assumption:在Supervised Learning,訓練資料都是從未知但固定的機率分佈所產生出來。
Learning task:
從某機率分佈產生k筆訓練資料,希望能找到規則以從未知的給予正確的標籤。
如果,則會得到誤差。